


첫 베가 아키텍쳐 훈련 가속기, 라데온 인스팅트 MI25
http://videocardz.com/64677/amd-announces-first-vega-accelerator-radeon-instinct-mi25-for-deep-learning

샤오미가 생각나기도 하고, 영국 "군정보부 6호실"도 생각나는 MI 라인업으로 베가가 처음 선을 보이게 되었습니다.
파스칼 P100도 그렇지만, 이 친구들은 그래픽카드가 아닌 그래픽카드 칩셋을 넣은 연산 장비입니다. 그래픽카드라는 이름 조차도 아니라 연산 "가속기" 입니다. 요게 뭐에 쓰라고 만든 물건이냐면 인공신경망 학습 중 "훈련" 단계에 쓰이는 연산을 가속하기 위한 장비입니다. 인공신경망은 "추론" 과 "훈련" 단계로 나뉘는데, 추론은 정확한 연산보다는 다양한 탐색을 위해 8비트 정수 연산(INT8)을 사용하고 훈련은 막대한 연산량 처리를 위해 16비트 부동소수점 연산(반정밀도 연산, FP16) 을 씁니다. 파스칼 P100과 마찬가지로 MI 라인업은 이 훈련 단계의 연산, 즉 반정밀도 부동소수점 연산 처리를 위한 장비입니다.

어떻게 저게 들어가는지만 봐도 사실 애초에 이게 데스크톱 용이 아님을 쉽게 알 수 있죠. 120개의 라데온 인스팅트 MI25 모듈을 넣어 3 페타플롭스급의 성능을 내는 미친 머신을 만들어냈다고 광고하는 것입니다.
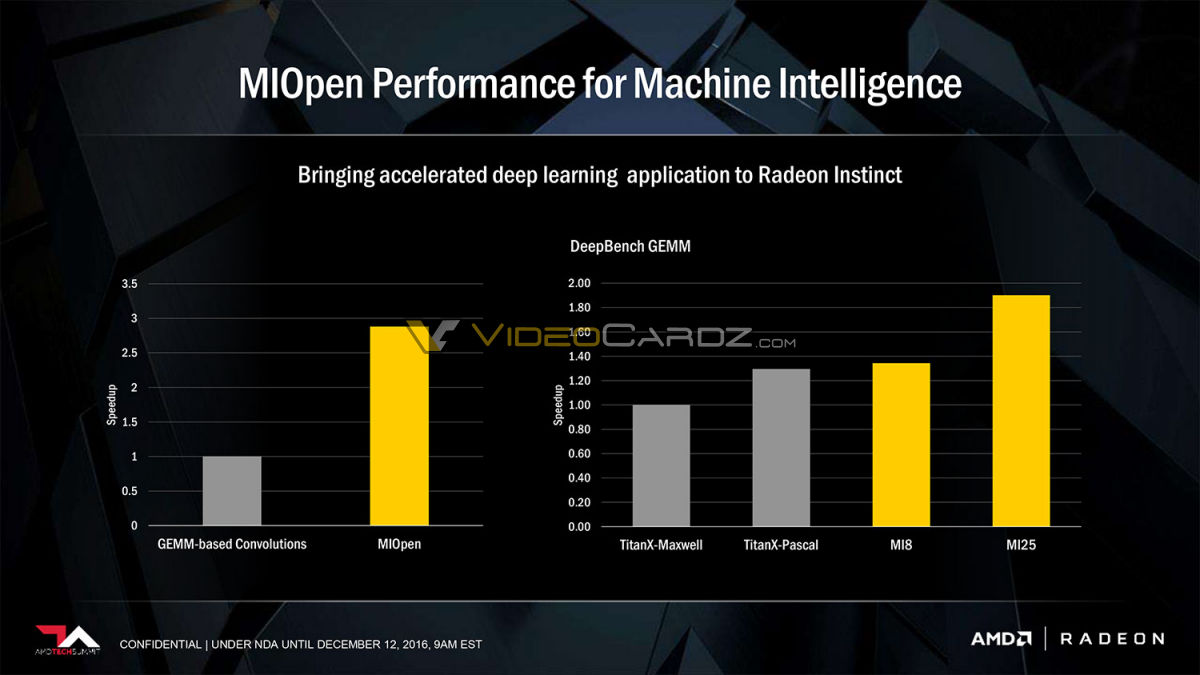
뭐 그래서 본래 목적에 맞게 쓴다면 딥러닝 벤치마크에서 소형 폼팩터 (전기도 덜먹고 우겨넣기 좋은) MI8(=라데온 나노)이 타이탄 XP를 앞서며, MI 25는 대략 1.5배정도 성능을 낼 수 있다는 것 같습니다. 사실 근데 타이탄XP는 정수 연산에 특화한 친구라... 비교 대상이 P100이었으면 좋을 뻔 했네요.
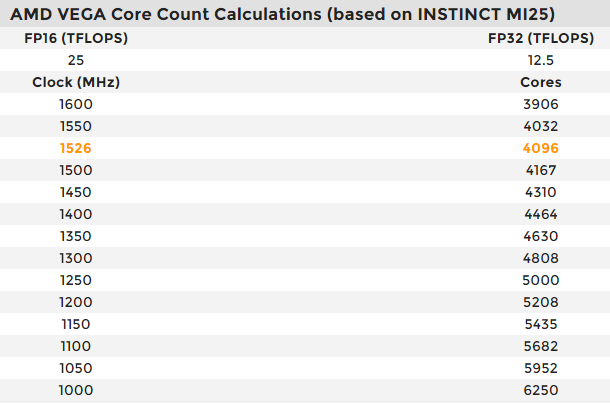
사실 이건 일개 게이머인 저와는 1g도 접점이 없는 이야기고, 이걸 통해 유추할 수 있는건 베가의 그래픽카드 성능입니다. MI 25의 반정밀도 성능이 이름대로 25 TFLops 라는 것은, 단정밀도 성능은 12.5TFLops 라는 뜻입니다. 이는 타이탄 XP의 10.5TFLops를 앞서는 성능입니다. 아마도 이 성능이 나오는 조합 중 가장 가능성이 높은 것은 제 생각에도 오렌지색 4096 SP @ 1526MHz 일 듯 합니다. 이렇게 되면 파스칼을 위협하는, 암드 GPU 역사상 유래없는 고클럭입니다.
| 엔비디아 | 연산성능 | 암드 | 연산성능 |
| GTX 950 | 1.7 TFLops | RX 460 | 1.9 TFLops |
| GTX 970 | 3.7 TFLops | RX 470 | 4.9 TFLops |
| GTX 1060 | 4.3 TFLops | RX 480 | 5.8 TFLops |
| GTX 1070 | 6.3 TFLops | R9 FuryX | 8.2 TFLops |
| GTX 1080 | 8.7 TFLops | MI25 12.5 TFLops | |
| 타이탄XP | 10.5 TFLops | ||
다만 표에서 보듯이 암드는 단정밀도 연산성능이 한참 낮은 엔비디아 카드와 동급으로 묶입니다. 베가 또한 게이밍 성능은 1080에 근접하지 않을까 싶습니다. 같은 SP 숫자로 FuryX를 $649에 낸 전례가 있긴 합니다만, 핀펫공정이라 얼마를 받을지는 모르겠네요. 그래도 드디어 1080의 아성을 넘볼수 있는 그래픽카드가 나온다면 재밌을 거 같습니다.
- 2019-07-26 10:16 이야기 > 좀비랜드 2 예고편 *1
- 2019-07-11 01:51 이야기 > 결국 질렀습니다 *18
- 2019-07-08 12:25 이야기 > AMD 나비, 하와이의 재림. 그러나... *6
- 2019-07-08 10:41 이야기 > 라이젠 마티스는 지금 사기엔 이르단 생각입니다 *18
- 2019-07-04 18:54 이야기 > SUPER? 그다지 수퍼하지 않은 수퍼지만... *24




- AMD,
 RX 460 코어 부활
RX 460 코어 부활

 내년 졸업작품으로 ConvNet을 사용하려던 차에 관심이 가네요. 클러스터로 구성하는 용자도 나올거 같고 기대됩니다.
내년 졸업작품으로 ConvNet을 사용하려던 차에 관심이 가네요. 클러스터로 구성하는 용자도 나올거 같고 기대됩니다.

 sewawa
sewawa  Please&
Please&  안녕하심니까
안녕하심니까  coyan
coyan  BlackRaven
BlackRaven 











ati, amd만 십여년을 넘게 쓰다가 최근 1060을 시작으로 1080쓰고 있지만
아직 제 감성은 amd에 남아 있습니다
제발 성능과 발열 전력 가격에서 1080를 넘어서는 카드가 나와주었으면 합니다